- Published on
History of Character Encoding

Table of Contents
- Overview
- C++ Encoding
- Historical Encodings
- 1960 - Initial Encodings
- 1964 - IBM 360
- 1964 - ASCII
- Shift JIS
- 1990 - Unicode Consortium
- 1990s - UTF-8
- Problems with UTF-8 Encoding
Overview
In the following blog, we will be covering what is a character and how we represent it. To start if off, lets take the case of how C++ encodes their characters.
C++ Encoding
To get started, lets use C++ character encodings as a sample case. In C++ when declaring char 'x' we can represent the x in ascii representation. In this case, the ascii integer 120.
- in this case the character corresponds to a small integer, and will be represented as an individual symbol
This implementation seems really simple but the problem of how to create the universal standard for what characters are and how we would uniformly represent them all has been worked on for decades, and is a complex problem.
Historical Encodings
Let's consider some historical examples of encodings to see how technology has developed to address the issues of each encoding format.
1960 - Initial Encodings
In 1960, we came to the standard that the numbers 0-63 represent a character.
A-Z(26)0-9(10)+-/(28)
Words were stored in a separate address for each word. Since the word size is 24bits, only the last six bits would be represented by characters, which caused good performance at the cost of space.
1964 - IBM 360
Introduced byte addressing which asserted that instead of having a separate address for each word, we would have a separate address for each byte (8-bit). This was great as it reduced the spacing issues as each byte address would not waste any space as the word size would be 32 or 64 bits (a multiple of the byte address).
Because of the 8-bit character address, IBM realized that they could create words with large combinations of characters. EBCDIC did not have continuous memory addresses within EBCDIC causing a lot of issues when referencing memory using arithmetic, consider int x = 'c'-'a'.
1964 - ASCII
ASCII used a 7-bit character set with the first bit being an exclusive or of the rest of the bits within the code. The reason why we want this parody bit, is if the encoding has been corrupted over the internet, the parody bit's corruption would signify the the ascii code had been modified and transmitted incorrectly.
The first four rows of ascii are called control characters that cannot be printed out. 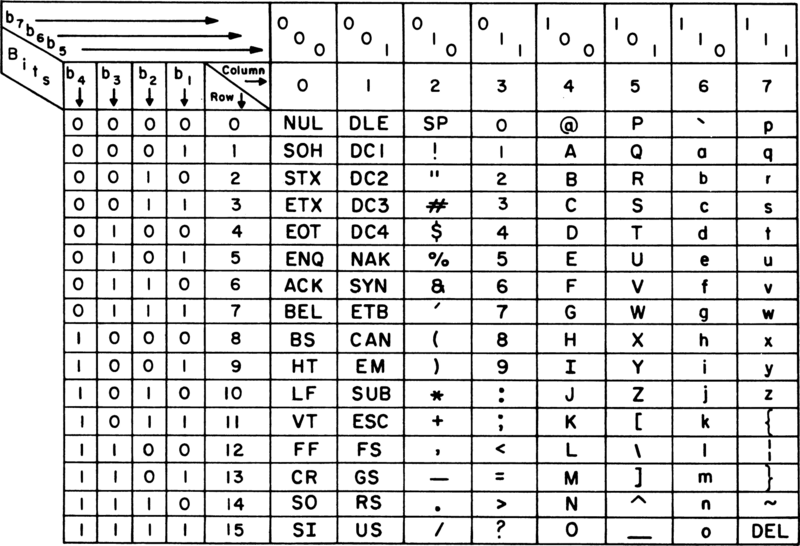
Addressing ASCII Issues
Issues with ASCII include addressing different language symbols. Consider the greek character . This would not be represented within ASCII but within Latin 1.
Latin 1 allowed for compatibility from things from the United States as they didn't remap the original ASCII encodings. A lot of changes happened with these encodings creating and ISO standard.
For more complex languages such as Chinese, 16-bit characters were used for larger more complex characters. This was necessary as the language had a much larger collection of different characters. The issue with the encoding, the file is bloated and it is not compatible with the other methods of file formatting.
Consider the following encodings of the word HELLO:
[0|H][0|e][0|L][0|l][0|O]- 16 bit representation[H][e][L][l][O]- 8 bit representation
So when you convert between the two, there is a lot of incompatibility.
Shift JIS
Alternate approaches include using the parody check bit to signify a different encoding rather than general ASCII. Shift JIS, a new encoding type used both 1-byte and 2-byte encodings within the ASCII characters.
- 1 byte ASCII + 2 changes (8 bits)
- 2 byte
[1|XXXX|XXXXX](16 bits)
The problem with ShiftJIS and EUC is you cannot go into the middle of a byte string and know where the characters are.
1990 - Unicode Consortium
The unicode consortium is a single agreed upon assignment for all of the characters in all human scripts. Unicode tried to unify Chinese, Japanese, and Korean causing many political problems. The number of assignments was around 146,000 which was not able to be represented with 1 byte or 2 byte encodings
1990s - UTF-8
Every multi-byte sequence containing greater than one byte representing a character has only non ascii bytes. When you land in the middle of a multi-byte sequence, you can easily see the boundries of multi-byte characters.
[0|X...]- ASCII Character[1|0|......]Continuation Byte[1|10|....]Length + Leading Byte where the number of 1 bytes at the start represent the length of the character encoding. (max of 4-byte sequences)
To clarify some things, when you use the length bit, you would follow it up with the continuation bytes that actually show the representations that you want. Now think about it, when you jump into this byte sequence, and run into something like [10|.....] you would realize the leading 10 represents a continuation byte and you would go back to until you reach a length byte to see how long the character sequence is.
Problems with UTF-8 Encoding
Attackers often exploit gaps in UTF-8 encoding. Suppose you have a 2-byte sequence [110|0000][10111111] which represents the ASCII DEL characters. This means that there are two ways to represent that character, (ASCII and the 2 byte encoding).
When you use functions like strcmp, and compare the two representations of the characters, it will return that they are different. Hackers often send incorrect representations of ASCII in UTF-8 to mess up programs with these comparisons with encoding. To address this, a lot of checking happens to ensure that the UTF-8 encoding is valid.
- Authors

- Name
- Apurva Shah
- Website
- apurvashah.org